AEWS 5주차 - EKS Autoscaling(CAS, CPA, Karpenter - 실습)
| 본 글은 가시다님이 진행하시는 AEWS(AWS EKS Workshop Study)를 참여하여 정리한 글입니다. 모르는 부분이 많아서 틀린 내용이 있다면 말씀 부탁드리겠습니다! |
CAS

CAS (Cluster Auto Scaler)가 동작하기 위해서는 노드들에 태그가 달려있어야합니다.
# k8s.io/cluster-autoscaler/enabled : true
# k8s.io/cluster-autoscaler/myeks : owned

# 현재 autoscaling(ASG) 정보 확인
# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='클러스터이름']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
# MaxSize 6개로 수정
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
# 배포 : Deploy the Cluster Autoscaler (CAS)
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
...
- ./cluster-autoscaler
- --v=4
- --stderrthreshold=info
- --cloud-provider=aws
- --skip-nodes-with-local-storage=false # 로컬 스토리지를 가진 노드를 autoscaler가 scale down할지 결정, false(가능!)
- --expander=least-waste # 노드를 확장할 때 어떤 노드 그룹을 선택할지를 결정, least-waste는 리소스 낭비를 최소화하는 방식으로 새로운 노드를 선택.
- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/<YOUR CLUSTER NAME>
...
# 변수 확인
sed -i -e "s|<YOUR CLUSTER NAME>|$CLUSTER_NAME|g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml# 확인
kubectl get pod -n kube-system | grep cluster-autoscaler
옵션
# (옵션) cluster-autoscaler 파드가 동작하는 워커 노드가 퇴출(evict) 되지 않게 설정
kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"
이제 샘플 디플로이먼트를 배포 후 replicaset을 증가시켜서 노드가 증가됨을 확인해봅니다.
# Deploy a Sample App
# We will deploy an sample nginx application as a ReplicaSet of 1 Pod
cat << EOF > nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EOF
kubectl apply -f nginx.yaml
kubectl get deployment/nginx-to-scaleout
# Scale our ReplicaSet
# Let’s scale out the replicaset to 15
kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
# 확인
kubectl get pods -l app=nginx -o wide --watch
kubectl -n kube-system logs -f deployment/cluster-autoscaler

replicaset이 늘어남에 따라 pod가 생성되었지만 6개가 pending인 상태입니다.
이유는 위의 node-viewer을 보면 cpu등 자원이 부족하기 떄문입니다.
약 3분이 지나고 노드가 3대 늘어나면서 모든 pod가 running으로 상태가 바뀌었습니다.

또한 콘솔의 Cloudtrail에서도 이러한 이벤트를 확인할 수 있습니다.

- Pending 상태의 파드가 생기는 타이밍에 처음으로 Cluster Autoscaler 이 동작한다
- 즉, Request 와 Limits 를 적절하게 설정하지 않은 상태에서는 실제 노드의 부하 평균이 낮은 상황에서도 스케일 아웃이 되거나, 부하 평균이 높은 상황임에도 스케일 아웃이 되지 않는다!
이전에 고객이 노드의 CPU 자원을 모두 사용했는데 왜 노드가 늘어나지 않았는지 물어본 경험이 있는데, 그때도 Request를 많이 잡고 있지만, 실제 노드의 평균 부하가 작아서 늘어나지 않은 경험이 있습니다. 이때는 다른 방도를 찾아야할 것 같습니다.
접은 글로 CA의 단점을 적겠습니다.
* 해당 스터디 내용 매우 잘 정리되어서 발췌했습니다.
- CA 문제점 : ASG에만 의존하고 노드 생성/삭제 등에 직접 관여 안함
- EKS에서 노드를 삭제 해도 인스턴스는 삭제 안됨
- 노드 축소 될 때 특정 노드가 축소 되도록 하기 매우 어려움 : pod이 적은 노드 먼저 축소, 이미 드레인 된 노드 먼저 축소
- 특정 노드를 삭제 하면서 동시에 노드 개수를 줄이기 어려움 : 줄일때 삭제 정책 옵션이 다양하지 않음
- 정책 미지원 시 삭제 방식(예시) : 100대 중 미삭제 EC2 보호 설정 후 삭제 될 ec2의 파드를 이주 후 scaling 조절로 삭제 후 원복
- 특정 노드를 삭제하면서 동시에 노드 개수를 줄이기 어려움
- 폴링 방식이기에 너무 자주 확장 여유를 확인 하면 API 제한에 도달할 수 있음
- 스케일링 속도가 느림
- Cluster Autoscaler 는 쿠버네티스 클러스터 자체의 오토 스케일링을 의미하며, 수요에 따라 워커 노드를 자동으로 추가하는 기능
- 언뜻 보기에 클러스터 전체나 각 노드의 부하 평균이 높아졌을 때 확장으로 보인다 → 함정! 🚧
- Pending 상태의 파드가 생기는 타이밍에 처음으로 Cluster Autoscaler 이 동작한다
- 즉, Request 와 Limits 를 적절하게 설정하지 않은 상태에서는 실제 노드의 부하 평균이 낮은 상황에서도 스케일 아웃이 되거나, 부하 평균이 높은 상황임에도 스케일 아웃이 되지 않는다!
- 기본적으로 리소스에 의한 스케줄링은 Requests(최소)를 기준으로 이루어진다. 다시 말해 Requests 를 초과하여 할당한 경우에는 최소 리소스 요청만으로 리소스가 꽉 차 버려서 신규 노드를 추가해야만 한다. 이때 실제 컨테이너 프로세스가 사용하는 리소스 사용량은 고려되지 않는다.
- 반대로 Request 를 낮게 설정한 상태에서 Limit 차이가 나는 상황을 생각해보자. 각 컨테이너는 Limits 로 할당된 리소스를 최대로 사용한다. 그래서 실제 리소스 사용량이 높아졌더라도 Requests 합계로 보면 아직 스케줄링이 가능하기 때문에 클러스터가 스케일 아웃하지 않는 상황이 발생한다.
- 여기서는 CPU 리소스 할당을 예로 설명했지만 메모리의 경우도 마찬가지다
CPA
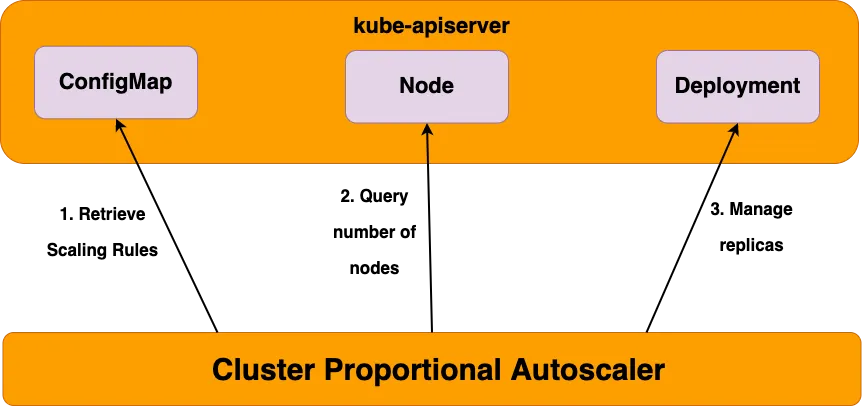
노드 수 증가에 비례하여 성능 처리가 필요한 애플리케이션(컨테이너/파드)를 수평으로 자동 확장합니다.
즉 coredns를 daemonset으로 배포하기에는 오버지만 설정한 정책(노드의 수)에 따라 증가할 수 있게끔합니다.
* 저는 현재 오류로 인해서 하기에 코드로만 대체하겠습니다.
#
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
# CPA규칙을 설정하고 helm차트를 릴리즈 필요
helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
# nginx 디플로이먼트 배포
cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT
kubectl apply -f cpa-nginx.yaml
# CPA 규칙 설정
cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
kubectl describe cm cluster-proportional-autoscaler
# 모니터링
watch -d kubectl get pod
# helm 업그레이드
helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
# 노드 5개로 증가
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
Karpenter
# 변수 설정
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.2.1"
export K8S_VERSION="1.32"
export AWS_PARTITION="aws" # if you are not using standard partitions, you may need to configure to aws-cn / aws-us-gov
export CLUSTER_NAME="gasida-karpenter-demo" # ${USER}-karpenter-demo
export AWS_DEFAULT_REGION="ap-northeast-2"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export TEMPOUT="$(mktemp)"
export ALIAS_VERSION="$(aws ssm get-parameter --name "/aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2023/x86_64/standard/recommended/image_id" --query Parameter.Value | xargs aws ec2 describe-images --query 'Images[0].Name' --image-ids | sed -r 's/^.*(v[[:digit:]]+).*$/\1/')"
# 확인
echo "${KARPENTER_NAMESPACE}" "${KARPENTER_VERSION}" "${K8S_VERSION}" "${CLUSTER_NAME}" "${AWS_DEFAULT_REGION}" "${AWS_ACCOUNT_ID}" "${TEMPOUT}" "${ALIAS_VERSION}"
cloudformation 배포
# CloudFormation 스택으로 IAM Policy/Role, SQS, Event/Rule 생성 : 3분 정도 소요
## IAM Policy : KarpenterControllerPolicy-gasida-karpenter-demo
## IAM Role : KarpenterNodeRole-gasida-karpenter-demo
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/cloudformation.yaml > "${TEMPOUT}" \
&& aws cloudformation deploy \
--stack-name "Karpenter-${CLUSTER_NAME}" \
--template-file "${TEMPOUT}" \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides "ClusterName=${CLUSTER_NAME}"
# 클러스터 생성 : EKS 클러스터 생성 15분 정도 소요
eksctl create cluster -f - <<EOF
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: ${CLUSTER_NAME}
region: ${AWS_DEFAULT_REGION}
version: "${K8S_VERSION}"
tags:
karpenter.sh/discovery: ${CLUSTER_NAME}
iam:
withOIDC: true
podIdentityAssociations:
- namespace: "${KARPENTER_NAMESPACE}"
serviceAccountName: karpenter
roleName: ${CLUSTER_NAME}-karpenter
permissionPolicyARNs:
- arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerPolicy-${CLUSTER_NAME}
iamIdentityMappings:
- arn: "arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}"
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
## If you intend to run Windows workloads, the kube-proxy group should be specified.
# For more information, see https://github.com/aws/karpenter/issues/5099.
# - eks:kube-proxy-windows
managedNodeGroups:
- instanceType: m5.large
amiFamily: AmazonLinux2023
name: ${CLUSTER_NAME}-ng
desiredCapacity: 2
minSize: 1
maxSize: 10
iam:
withAddonPolicies:
externalDNS: true
addons:
- name: eks-pod-identity-agent
EOF
# eks 배포 확인
eksctl get cluster

# 동작 확인을 위한 kubeopsview
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=LoadBalancer --set env.TZ="Asia/Seoul" --namespace kube-system
echo -e "http://$(kubectl get svc -n kube-system kube-ops-view -o jsonpath="{.status.loadBalancer.ingress[0].hostname}"):8080/#scale=1.5"
open "http://$(kubectl get svc -n kube-system kube-ops-view -o jsonpath="{.status.loadBalancer.ingress[0].hostname}"):8080/#scale=1.5"
Karpenter 설치
# Logout of helm registry to perform an unauthenticated pull against the public ECR
helm registry logout public.ecr.aws
# Karpenter 설치를 위한 변수 설정 및 확인
export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name "${CLUSTER_NAME}" --query "cluster.endpoint" --output text)"
export KARPENTER_IAM_ROLE_ARN="arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
echo "${CLUSTER_ENDPOINT} ${KARPENTER_IAM_ROLE_ARN}"
# karpenter 설치
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
# 확인
helm list -n kube-system
- Karpenter는 노드 용량 추적을 위해 클러스터의 CloudProvider 머신과 CustomResources 간의 매핑을 만듭니다. 이 매핑이 일관되도록 하기 위해 Karpenter는 다음 태그 키를 활용합니다.
- karpenter.sh/managed-by
- karpenter.sh/nodepool
- kubernetes.io/cluster/${CLUSTER_NAM

Pod Identity에서 Karpenter에 대한 정책을 담은 role과 연결이 되어있습니다.
(이는 Addon을 설치합니다.)

Node Pool을 생성
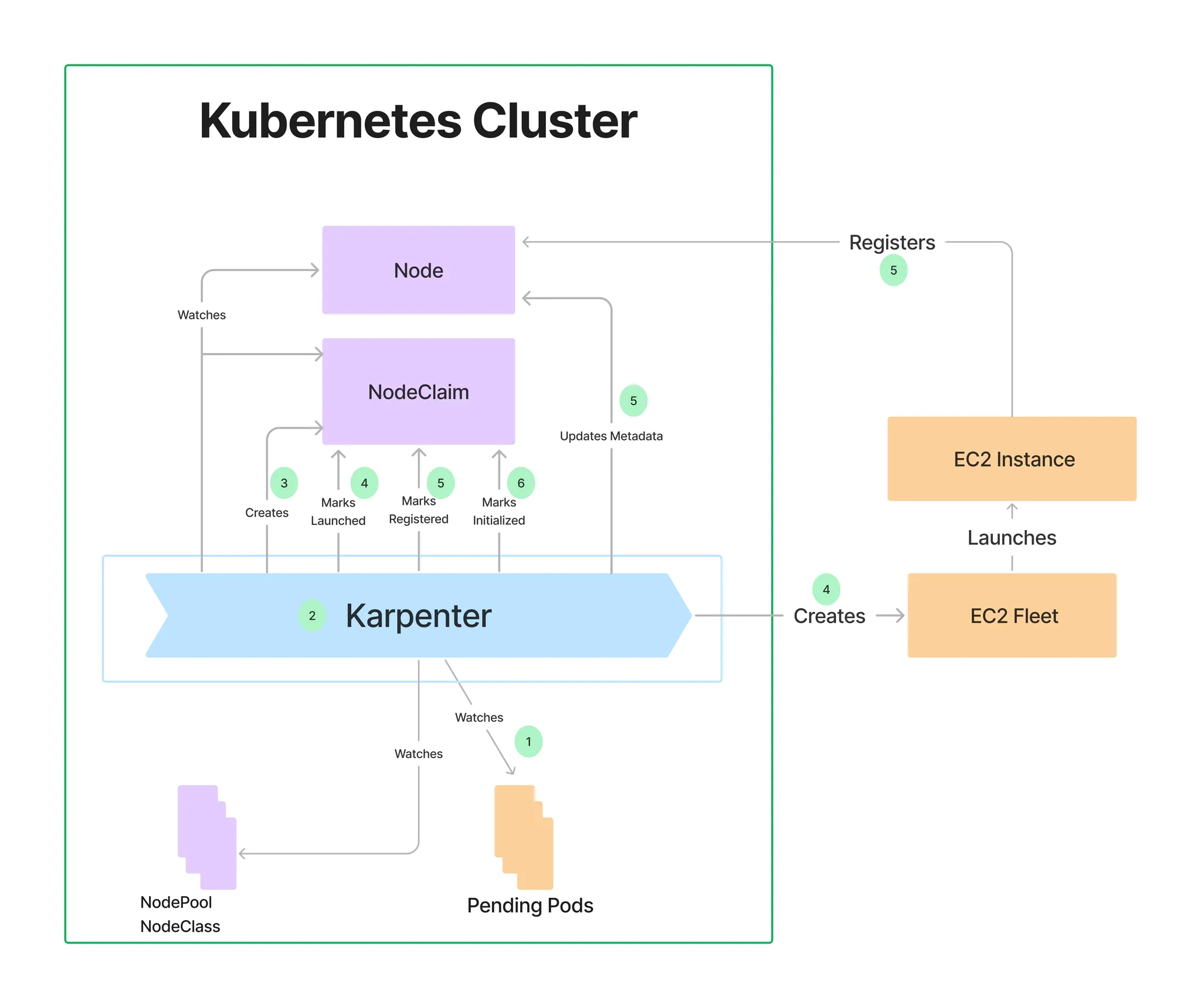
- 관리 리소스는 securityGroupSelector and subnetSelector로 찾음
- consolidationPolicy : 미사용 노드 정리 정책, 데몬셋 제외
관련 내용
아래 명령을 사용하여 기본 NodePool을 만듭니다. 이 NodePool은 노드를 시작하는 데 사용되는 리소스를 검색하기 위해 securityGroupSelectorTerms및 를 사용합니다. 위 명령 에서 subnetSelectorTerms태그를 적용했습니다 . 이러한 리소스가 클러스터 간에 공유되는 방식에 따라 다른 태그 지정 체계를 사용해야 할 수 있습니다.karpenter.sh/discovery
consolidationPolicy은 Karpenter가 노드를 제거하고 교체하여 클러스터 비용을 줄이도록 구성합니다. 결과적으로 통합은 클러스터의 모든 빈 노드를 종료합니다. 이 동작은 로 설정하여 Karpenter에게 노드를 통합해서는 안 된다고 말함으로써 비활성화할 수 있습니다 .
#
echo $ALIAS_VERSION
v20250228
#
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 720h # 30 * 24h = 720h
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@${ALIAS_VERSION}" # ex) al2023@latest
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
# 확인
kubectl get nodepool,ec2nodeclass,nodeclaims

샘플 애플리케이션 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
securityContext:
allowPrivilegeEscalation: false
EOF
# 애플리케이션 scaleup
kubectl get pod
kubectl scale deployment inflate --replicas 5
로그 확인
# 출력 로그 분석해보자!
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller


새로운 노드가 증설되었습니다.
앞서 말한 것과 같이 이렇게 배포된 노드는 언급한 태그들을 가지고 있습니다.

replicaset을 20으로 더 높입니다.



사진과 같이 미리 정의해둔 인스턴스 유형중 c5a.4xlarge를 띄우면서 파드를 running 시켰습니다.
그리고 프로메테우스에서도 karpenter 관련 내용들을 확인이 가능합니다.
arpenter_cluster_state_node_count{instance="192.168.17.154:8080", job="karpenter"}
